Intro to RAG
What Is Retrieval-Augmented Generation (RAG)?
Engaging in a conversation with a company’s AI assistant can be frustrating. Chatbots give themselves away by returning generic responses that often don’t answer the question. This is because Large language models (LLMs), like OpenAI’s GPT models, excel at general language tasks but have trouble answering specific questions for several reasons:
- LLMs have a broad knowledge base but often lack in-depth industry- or organization-specific context.
- LLMs may generate responses that are incorrect, known as hallucinations.
- LLMs lack explainability, as they can’t verify, trace, or cite sources.
- An LLM’s knowledge is based on static training data that doesn’t update with real-time information.
This doesn’t have to be the case. Imagine a different scenario: interacting with a chatbot that provides detailed, precise responses. This chatbot sounds like a human with deep institutional knowledge about the company and its products and policies. This chatbot is actually helpful. The second scenario is possible through a machine learning approach called Retrieval-Augmented Generation (RAG).
RAG is a technique that enhances Large Language Model (LLM) responses by retrieving source information from external data stores to augment generated responses. These data stores, including databases, documents, or websites, may contain domain-specific, proprietary data that enable the LLM to locate and summarize specific, contextual information beyond the data the LLM was trained on.
RAG applications are becoming the industry standard for organizations that want smarter generative AI applications. With RAG, we can reduce hallucination, provide explainability, draw upon the most recent data, and expand the range of what our LLM can answer. As we improve the quality and specificity of its response, we also create a better user experience.
How Does RAG Work?
At a high level, the RAG architecture involves 3 key processes:
- understanding queries: the process begins when a user asks a question. The query goes through the LLM API to the RAG application, which analyzes it to understand the user’s intent and determine what information to look for.
- retrieving information: the application uses advanced algorithms to find the most relevant pieces of information in the company’s database. These algorithms match vector embeddings based on semantic similarity to identify the information that can best answer the user’s question.
- generating responses: the application combines the retrieved information with the user’s original prompt to create a more detailed and context-rich prompt. It then uses the new prompt to generate a response tailored to the organization’s internal data.
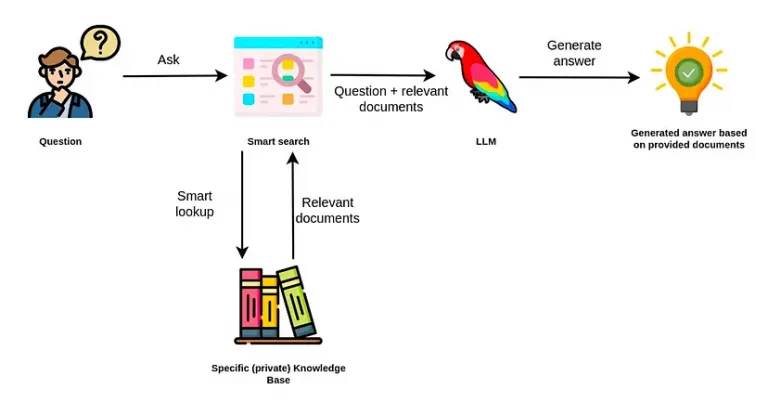
Before implementing an RAG application, it’s important to clean up our data to make it easy for the RAG application to quickly search and retrieve relevant information. This process is called data indexing.
Frameworks like LangChain make it easy to build RAG applications by providing a unified interface to connect LLMs to external databases via APIs. Neo4j vector index on the LangChain library helps simplify the indexing process.
RAG is Not the Final Answer
People just started building RAG systems would feel like magic: retrieve the right documents and let the model generate. No hallucinations or hand holding, and we get clean and grounded answers. But then the cracks showed over time. RAG worked fine on simple questions, but when the input is longer and poorly structured, or when multi-step reasoning is involved, it starts to struggle. Tweaking chunk sizes or plying with hybrid search for example have been shown to improve the output only slightly.
The core issue is that RAG retrieves but it doesn’t reason or plan. Due to its limitations, RAG has been widely regarded a starting point, not a solution. if we are inputting real world queries, we need memory and planning. One better example would be to wrap RAG in a task planner instead of endless fine-tuning.
For example, if we use RAG with some technical manuals and ask “explain this differently, make it easier to digest, and give me a class on this subject as an instructor would”. That is going to be a great use case for RAG when paired with a strong prompt strategy and clear retrieval scope. If the technical manuals are well-structured and chunked, a RAG system can definitely retrieve relevant sections and reframe them into simplified, instructional content. For more dynamic behavior like teaching styles, adapting explanations to learner feedback, or building a step-by-step curriculum, however, we would likely benefit from layering in agentic behavior or an instructional persona agent on top of RAG. That’s where combining memory, reasoning, and planning starts to elevate the experience beyond static retrieval. Googles Notebook LM would be a good playground to demonstrate this.
This is not RAG’s fault, because “RAG cannot plan” is like saying Elasticsearch or Google search cannot plan. These are information retrieval systems, they are not supposed to plan anything but to retrieve information. If we want planning capabilities, we should add agents and that is a very different level of complexity. Therefore people interested in exploring this direction is recommended checking out Building Business-Ready Generative AI Systems. It goes deep into combining RAG with agentic design, memory, and reasoning flows basically everything that starts where traditional RAG ends.
At the end of the day, RAG should be a component of agentic frameworks that we use to get our system to reply appropriately beyond the information retrieval. Planning would be a true AI feature, LLMs are not it